


How Jeff Bezos wins meetings over

We've all been there: You propose a suggestion to your team at a meeting, and most people appear on board, but a handful or small minority aren't. How can we achieve collective buy-in when we need to go forward but don't know how to deal with some team members' perceived intransigence?
Steps:
Investigate the divergent opinions: Begin by sincerely attempting to comprehend the viewpoint of your disagreeing coworkers. Maybe it makes sense to switch horses in the middle of the race. Have you completely overlooked a blind spot, such as a political concern that could arise as an unexpected result of proceeding? This is crucial to ensure that the person or people feel heard as well as to advance the goals of the team. Sometimes all individuals need is a little affirmation before they fully accept your point of view.
It says a lot about you as a leader to be someone who always lets the perceived greatest idea win, regardless of the originating channel, if after studying and evaluating you see the necessity to align with the divergent position.
If, after investigation and assessment, you determine that you must adhere to the original strategy, we go to Step 2.
2. Disagree and Commit: Jeff Bezos, CEO of Amazon, has had this experience, and Julie Zhuo describes how he handles it in her book The Making of a Manager.
It's OK to disagree when the team is moving in the right direction, but it's not OK to accidentally or purposefully damage the team's efforts because you disagree. Let the team know your opinion, but then help them achieve company goals even if they disagree. Unknown. You could be wrong in today's ever-changing environment.
So next time you have a team member who seems to be dissenting and you've tried the previous tactics, you may ask the individual in the meeting I understand you but I don't want us to leave without you on board I need your permission to commit to this approach would you give us your commitment?
More on Leadership

Will Lockett
2 years ago • 3 min read
Tesla recently disclosed its greatest secret.

The VP has revealed a secret that should frighten the rest of the EV world.
Tesla led the EV revolution. Elon Musk's invention offers a viable alternative to gas-guzzlers. Tesla has lost ground in recent years. VW, BMW, Mercedes, and Ford offer EVs with similar ranges, charging speeds, performance, and cost. Tesla's next-generation 4680 battery pack, Roadster, Cybertruck, and Semi were all delayed. CATL offers superior batteries than the 4680. Martin Viecha, Tesla's Vice President, recently told Business Insider something that startled the EV world and will establish Tesla as the EV king.
Viecha mentioned that Tesla's production costs have dropped 57% since 2017. This isn't due to cheaper batteries or devices like Model 3. No, this is due to amazing factory efficiency gains.
Musk wasn't crazy to want a nearly 100% automated production line, and Tesla's strategy of sticking with one model and improving it has paid off. Others change models every several years. This implies they must spend on new R&D, set up factories, and modernize service and parts systems. All of this costs a ton of money and prevents them from refining production to cut expenses.
Meanwhile, Tesla updates its vehicles progressively. Everything from the backseats to the screen has been enhanced in a 2022 Model 3. Tesla can refine, standardize, and cheaply produce every part without changing the production line.
In 2017, Tesla's automobile production averaged $84,000. In 2022, it'll be $36,000.
Mr. Viecha also claimed that new factories in Shanghai and Berlin will be significantly cheaper to operate once fully operating.
Tesla's hand is visible. Tesla selling $36,000 cars for $60,000 This barely beats the competition. Model Y long-range costs just over $60,000. Tesla makes $24,000+ every sale, giving it a 40% profit margin, one of the best in the auto business.
VW I.D4 costs about the same but makes no profit. Tesla's rivals face similar challenges. Their EVs make little or no profit.
Tesla costs the same as other EVs, but they're in a different league.
But don't forget that the battery pack accounts for 40% of an EV's cost. Tesla may soon fully utilize its 4680 battery pack.
The 4680 battery pack has larger cells and a unique internal design. This means fewer cells are needed for a car, making it cheaper to assemble and produce (per kWh). Energy density and charge speeds increase slightly.
Tesla underestimated the difficulty of making this revolutionary new cell. Each time they try to scale up production, quality drops and rejected cells rise.
Tesla recently installed this battery pack in Model Ys and is scaling production. If they succeed, Tesla battery prices will plummet.
Tesla's Model Ys 2170 battery costs $11,000. The same size pack with 4680 cells costs $3,400 less. Once scaled, it could be $5,500 (50%) less. The 4680 battery pack could reduce Tesla production costs by 20%.
With these cost savings, Tesla could sell Model Ys for $40,000 while still making a profit. They could offer a $25,000 car.
Even with new battery technology, it seems like other manufacturers will struggle to make EVs profitable.
Teslas cost about the same as competitors, so don't be fooled. Behind the scenes, they're still years ahead, and the 4680 battery pack and new factories will only increase that lead. Musk faces a first. He could sell Teslas at current prices and make billions while other manufacturers struggle. Or, he could massively undercut everyone and crush the competition once and for all. Tesla and Elon win.

Alison Randel
2 years ago • 6 min read
Raising the Bar on Your 1:1s

Managers spend much time in 1:1s. Most team members meet with supervisors regularly. 1:1s can help create relationships and tackle tough topics. Few appreciate the 1:1 format's potential. Most of the time, that potential is spent on small talk, surface-level updates, and ranting (Ugh, the marketing team isn’t stepping up the way I want them to).
What if you used that time to have deeper conversations and important insights? What if change was easy?
This post introduces a new 1:1 format to help you dive deeper, faster, and develop genuine relationships without losing impact.
A 1:1 is a chat, you would assume. Why use structure to talk to a coworker? Go! I know how to talk to people. I can write. I've always written. Also, This article was edited by Zoe.
Before you discard something, ask yourself if there's a good reason not to try anything new. Is the 1:1 only a talk, or do you want extra benefits? Try the steps below to discover more.
I. Reflection (5 minutes)
Context-free, broad comments waste time and are useless. Instead, give team members 5 minutes to write these 3 prompts.
What's effective?
What is decent but could be improved?
What is broken or missing?
Why these? They encourage people to be honest about all their experiences. Answering these questions helps people realize something isn't working. These prompts let people consider what's working.
Why take notes? Because you get more in less time. Will you feel awkward sitting quietly while your coworker writes? Probably. Persevere. Multi-task. Take a break from your afternoon meeting marathon. Any awkwardness will pay off.
What happens? After a few minutes of light conversation, create a template like the one given here and have team members fill in their replies. You can pre-share the template (with the caveat that this isn’t meant to take much prep time). Do this with your coworker: Answer the prompts. Everyone can benefit from pondering and obtaining guidance.
This step's output.

Part II: Talk (10-20 minutes)
Most individuals can explain what they see but not what's behind an answer. You don't like a meeting. Why not? Marketing partnership is difficult. What makes working with them difficult? I don't recommend slandering coworkers. Consider how your meetings, decisions, and priorities make work harder. The excellent stuff too. You want to know what's humming so you can reproduce the magic.
First, recognize some facts.
Real power dynamics exist. To encourage individuals to be honest, you must provide a safe environment and extend clear invites. Even then, it may take a few 1:1s for someone to feel secure enough to go there in person. It is part of your responsibility to admit that it is normal.
Curiosity and self-disclosure are crucial. Most leaders have received training to present themselves as the authorities. However, you will both benefit more from the dialogue if you can be open and honest about your personal experience, ask questions out of real curiosity, and acknowledge the pertinent sacrifices you're making as a leader.
Honesty without bias is difficult and important. Due to concern for the feelings of others, people frequently hold back. Or if they do point anything out, they do so in a critical manner. The key is to be open and unapologetic about what you observe while not presuming that your viewpoint is correct and that of the other person is incorrect.
Let's go into some prompts (based on genuine conversations):
“What do you notice across your answers?”
“What about the way you/we/they do X, Y, or Z is working well?”
“ Will you say more about item X in ‘What’s not working?’”
“I’m surprised there isn’t anything about Z. Why is that?”
“All of us tend to play some role in maintaining certain patterns. How might you/we be playing a role in this pattern persisting?”
“How might the way we meet, make decisions, or collaborate play a role in what’s currently happening?”
Consider the preceding example. What about the Monday meeting isn't working? Why? or What about the way we work with marketing makes collaboration harder? Remember to share your honest observations!
Third section: observe patterns (10-15 minutes)
Leaders desire to empower their people but don't know how. We also have many preconceptions about what empowerment means to us and how it works. The next phase in this 1:1 format will assist you and your team member comprehend team power and empowerment. This understanding can help you support and shift your team member's behavior, especially where you disagree.
How to? After discussing the stated responses, ask each team member what they can control, influence, and not control. Mark their replies. You can do the same, adding colors where you disagree.
This step's output.

Next, consider the color constellation. Discuss these questions:
Is one color much more prevalent than the other? Why, if so?
Are the colors for the "what's working," "what's fine," and "what's not working" categories clearly distinct? Why, if so?
Do you have any disagreements? If yes, specifically where does your viewpoint differ? What activities do you object to? (Remember, there is no right or wrong in this. Give explicit details and ask questions with curiosity.)
Example: Based on the colors, you can ask, Is the marketing meeting's quality beyond your control? Were our marketing partners consulted? Are there any parts of team decisions we can control? We can't control people, but have we explored another decision-making method? How can we collaborate and generate governance-related information to reduce work, even if the requirement for prep can't be eliminated?
Consider the top one or two topics for this conversation. No 1:1 can cover everything, and that's OK. Focus on the present.
Part IV: Determine the next step (5 minutes)
Last, examine what this conversation means for you and your team member. It's easy to think we know the next moves when we don't.
Like what? You and your teammate answer these questions.
What does this signify moving ahead for me? What can I do to change this? Make requests, for instance, and see how people respond before thinking they won't be responsive.
What demands do I have on other people or my partners? What should I do first? E.g. Make a suggestion to marketing that we hold a monthly retrospective so we can address problems and exchange input more frequently. Include it on the meeting's agenda for next Monday.
Close the 1:1 by sharing what you noticed about the chat. Observations? Learn anything?
Yourself, you, and the 1:1
As a leader, you either reinforce or disrupt habits. Try this template if you desire greater ownership, empowerment, or creativity. Consider how you affect surrounding dynamics. How can you expect others to try something new in high-stakes scenarios, like meetings with cross-functional partners or senior stakeholders, if you won't? How can you expect deep thought and relationship if you don't encourage it in 1:1s? What pattern could this new format disrupt or reinforce?
Fight reluctance. First attempts won't be ideal, and that's OK. You'll only learn by trying.

Sammy Abdullah
3 years ago • 54 s read
Payouts to founders at IPO
How much do startup founders make after an IPO? We looked at 2018's major tech IPOs. Paydays aren't what founders took home at the IPO (shares are normally locked up for 6 months), but what they were worth at the IPO price on the day the firm went public. It's not cash, but it's nice. Here's the data.
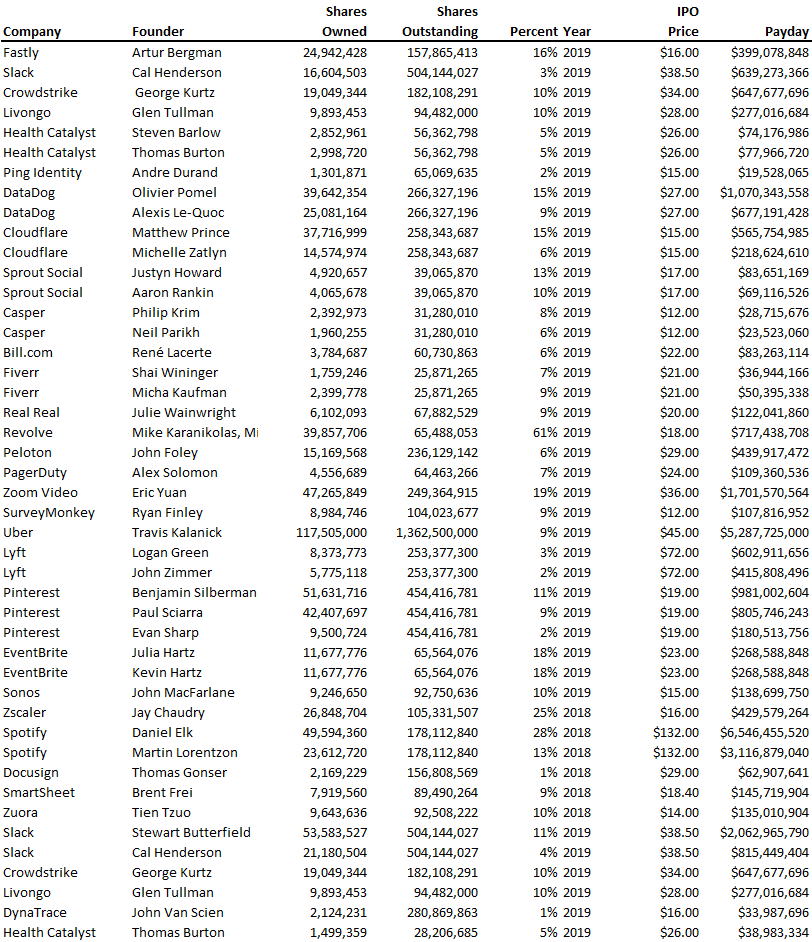
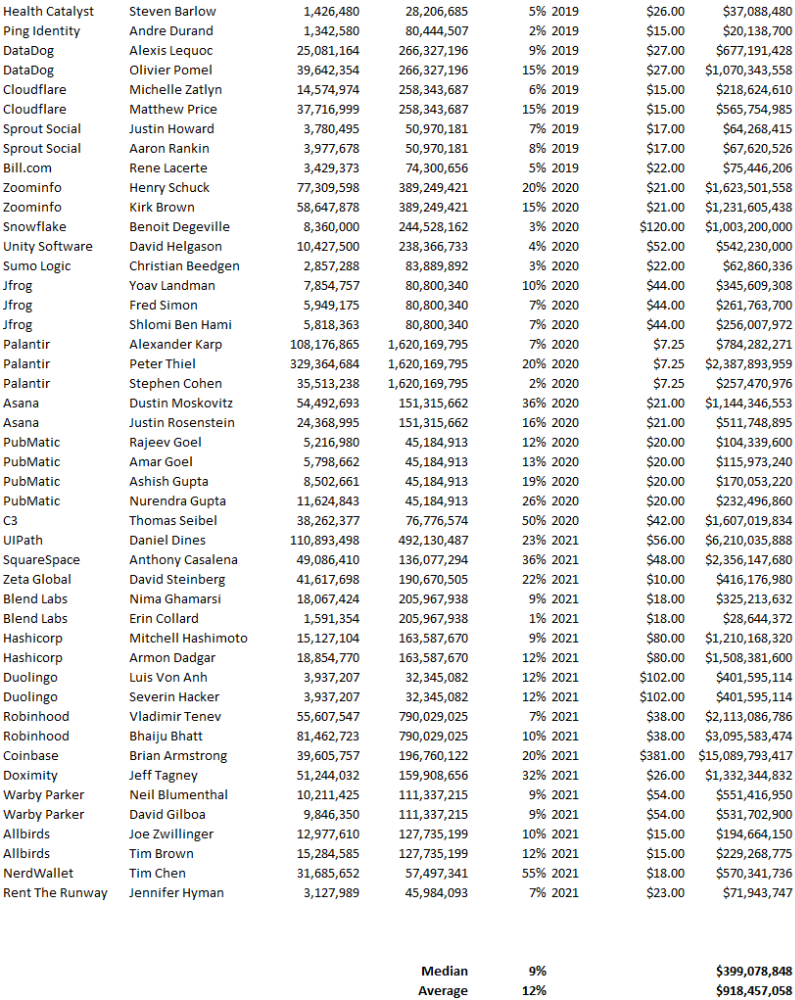
Several points are noteworthy.
Huge payoffs. Median and average pay were $399m and $918m. Average and median homeownership were 9% and 12%.
Coinbase, Uber, UI Path. Uber, Zoom, Spotify, UI Path, and Coinbase founders raised billions. Zoom's founder owned 19% and Spotify's 28% and 13%. Brian Armstrong controlled 20% of Coinbase at IPO and was worth $15bn. Preserving as much equity as possible by staying cash-efficient or raising at high valuations also helps.
The smallest was Ping. Ping's compensation was the smallest. Andre Duand owned 2% but was worth $20m at IPO. That's less than some billion-dollar paydays, but still good.
IPOs can be lucrative, as you can see. Preserving equity could be the difference between a $20mm and $15bln payday (Coinbase).
You might also like
Dmytro Spilka
2 years ago • 3 min read
Why NFTs Have a Bright Future Away from Collectible Art After Punks and Apes

After a crazy second half of 2021 and significant trade volumes into 2022, the market for NFT artworks like Bored Ape Yacht Club, CryptoPunks, and Pudgy Penguins has begun a sharp collapse as market downturns hit token values.
DappRadar data shows NFT monthly sales have fallen below $1 billion since June 2021. OpenSea, the world's largest NFT exchange, has seen sales volume decline 75% since May and is trading like July 2021.
Prices of popular non-fungible tokens have also decreased. Bored Ape Yacht Club (BAYC) has witnessed volume and sales drop 63% and 15%, respectively, in the past month.
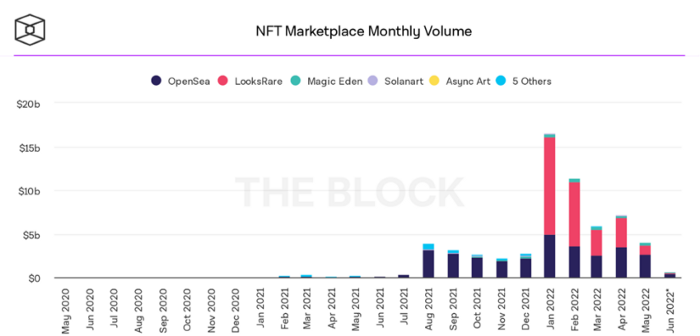
BeInCrypto analysis shows market decline. May 2022 cryptocurrency marketplace volume was $4 billion, according to a news platform. This is a sharp drop from April's $7.18 billion.
OpenSea, a big marketplace, contributed $2.6 billion, while LooksRare, Magic Eden, and Solanart also contributed.
NFT markets are digital platforms for buying and selling tokens, similar stock trading platforms. Although some of the world's largest exchanges offer NFT wallets, most users store their NFTs on their favorite marketplaces.
In January 2022, overall NFT sales volume was $16.57 billion, with LooksRare contributing $11.1 billion. May 2022's volume was $12.57 less than January, a 75% drop, and June's is expected to be considerably smaller.
A World Based on Utility
Despite declines in NFT trading volumes, not all investors are negative on NFTs. Although there are uncertainties about the sustainability of NFT-based art collections, there are fewer reservations about utility-based tokens and their significance in technology's future.
In June, business CEO Christof Straub said NFTs may help artists monetize unreleased content, resuscitate catalogs, establish deeper fan connections, and make processes more efficient through technology.
We all know NFTs can't be JPEGs. Straub noted that NFT music rights can offer more equitable rewards to musicians.
Music NFTs are here to stay if they have real value, solve real problems, are trusted and lawful, and have fair and sustainable business models.
NFTs can transform numerous industries, including music. Market opinion is shifting towards tokens with more utility than the social media artworks we're used to seeing.
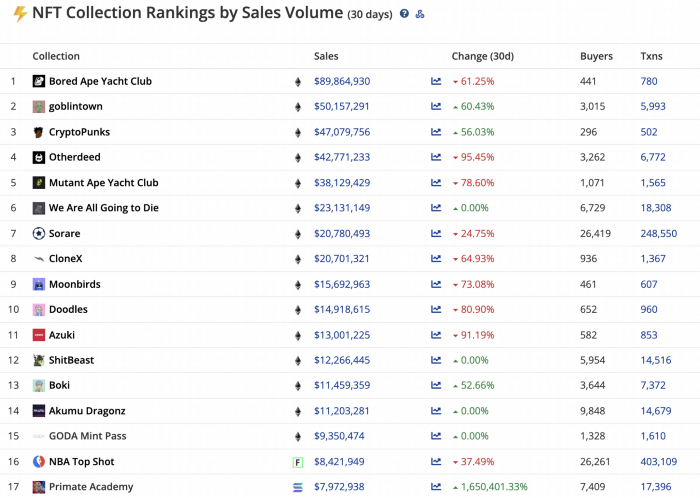
While the major NFT names remain dominant in terms of volume, new utility-based initiatives are emerging as top 20 collections.
Otherdeed, Sorare, and NBA Top Shot are NFT-based games that rank above Bored Ape Yacht Club and Cryptopunks.
Users can switch video NFTs of basketball players in NBA Top Shot. Similar efforts are emerging in the non-fungible landscape.
Sorare shows how NFTs can support a new way of playing fantasy football, where participants buy and swap trading cards to create a 5-player team that wins rewards based on real-life performances.
Sorare raised 579.7 million in one of Europe's largest Series B financing deals in September 2021. Recently, the platform revealed plans to expand into Major League Baseball.
Strong growth indications suggest a promising future for NFTs. The value of art-based collections like BAYC and CryptoPunks may be questioned as markets become diluted by new limited collections, but the potential for NFTs to become intrinsically linked to tangible utility like online gaming, music and art, and even corporate reward schemes shows the industry has a bright future.

Peter Steven Ho
3 years ago • 4 min read
Thank You for 21 Fantastic Years, iPod
Apple's latest revelation may shock iPod fans and former owners.

Apple discontinued the iPod touch on May 11, 2022. After 21 years, Apple killed the last surviving iPod, a device Steve Jobs believed would revolutionize the music industry.
Jobs was used to making bold predictions, but few expected Apple's digital music player to change the music industry. It did.
This chaos created new business opportunities. Spotify, YouTube, and Amazon are products of that chaotic era.
As the digital landscape changes, so do consumers, and the iPod has lost favor. I'm sure Apple realizes the importance of removing an icon. The iPod was Apple like the Mac and iPhone. I think it's bold to retire such a key Apple cornerstone. What would Jobs do?
iPod evolution across the ages
Here's an iPod family tree for all you enthusiasts.

iPod vintage (Oct 2001 to Sep 2014, 6 generations)
The original iPod had six significant upgrades since 2001. Apple announced an 80 GB ($249) and 160 GB ($349) iPod classic in 2007.
Apple updated the 80 GB model with a 120 GB device in September 2008. Apple upgraded the 120 GB model with a 160 GB variant a year later (2009). This was the last iteration, and Apple discontinued the classic in September 2014.
iPod nano (Jan 2004 to Sep 2005, 2 generations)
Apple debuted a smaller, brightly-colored iPod in 2004. The first model featured 4 GB, enough for 1,000 songs.
Apple produced a new 4 GB or 6 GB iPod mini in February 2005 and discontinued it in September when they released a better-looking iPod nano.
iTouch nano (Sep 2005 to July 2017, 7 generations)
I loved the iPod nano. It was tiny and elegant with enough tech to please most music aficionados, unless you carry around your complete music collection.

Apple owed much of the iPod nano's small form and success to solid-state flash memory. Flash memory doesn't need power because it has no moving parts. This makes the iPod nano more durable than the iPod classic and mini, which employ hard drives.
Apple manufactured seven generations of the iPod nano, improving its design, display screen, memory, battery, and software, but abandoned it in July 2017 due to dwindling demand.
Shuffle iPod (Jan 2005 to Jul 2017, 4 generations)
The iPod shuffle was entry-level. It was a simple, lightweight, tiny music player. The iPod shuffle was perfect for lengthy bike trips, runs, and hikes.

Apple sold 10 million iPod shuffles in the first year and kept making them for 12 years, through four significant modifications.
iOS device (Sep 2007 to May 2022, 7 generations)
The iPod touch's bigger touchscreen interface made it a curious addition to the iPod family. The iPod touch resembled an iPhone more than the other iPods, making them hard to tell apart.
Many were dissatisfied that Apple removed functionality from the iPod touch to avoid making it too similar to the iPhone. Seven design improvements over 15 years brought the iPod touch closer to the iPhone, but not completely.
The iPod touch uses the same iOS operating system as the iPhone, giving it access to many apps, including handheld games.
The iPod touch's long production run is due to the next generation of music-loving gamers.
What made the iPod cool
iPod revolutionized music listening. It was the first device to store and play MP3 music, allowing you to carry over 1,000 songs anywhere.
The iPod changed consumer electronics with its scroll wheel and touchscreen. Jobs valued form and function equally. He showed people that a product must look good to inspire an emotional response and ignite passion.
The elegant, tiny iPod was a tremendous sensation when it arrived for $399 in October 2001. Even at this price, it became a must-have for teens to CEOs.
It's hard to identify any technology that changed how music was downloaded and played like the iPod. Apple iPod and iTunes had 63% of the paid music download market in the fourth quarter of 2012.
The demise of the iPod was inevitable
Apple discontinuing the iPod touch after 21 years is sad. This ends a 00s music icon.
Jobs was a genius at anticipating market needs and opportunities, and Apple launched the iPod at the correct time.
Few consumer electronics items have had such a lasting impact on music lovers and the music industry as the iPod.
Smartphones and social media have contributed to the iPod's decline. Instead of moving to the music, the new generation of consumers is focused on social media. They're no longer passive content consumers; they're active content creators seeking likes and followers. Here, the smartphone has replaced the iPod.
It's hard not to feel a feeling of loss, another part of my adolescence now forgotten by the following generation.
So, if you’re lucky enough to have a working iPod, hang on to that relic and enjoy the music and the nostalgia.

Dmitrii Eliuseev
2 years ago • 11 min read
Creating Images on Your Local PC Using Stable Diffusion AI
Deep learning-based generative art is being researched. As usual, self-learning is better. Some models, like OpenAI's DALL-E 2, require registration and can only be used online, but others can be used locally, which is usually more enjoyable for curious users. I'll demonstrate the Stable Diffusion model's operation on a standard PC.

Let’s get started.
What It Does
Stable Diffusion uses numerous components:
A generative model trained to produce images is called a diffusion model. The model is incrementally improving the starting data, which is only random noise. The model has an image, and while it is being trained, the reversed process is being used to add noise to the image. Being able to reverse this procedure and create images from noise is where the true magic is (more details and samples can be found in the paper).
An internal compressed representation of a latent diffusion model, which may be altered to produce the desired images, is used (more details can be found in the paper). The capacity to fine-tune the generation process is essential because producing pictures at random is not very attractive (as we can see, for instance, in Generative Adversarial Networks).
A neural network model called CLIP (Contrastive Language-Image Pre-training) is used to translate natural language prompts into vector representations. This model, which was trained on 400,000,000 image-text pairs, enables the transformation of a text prompt into a latent space for the diffusion model in the scenario of stable diffusion (more details in that paper).
This figure shows all data flow:
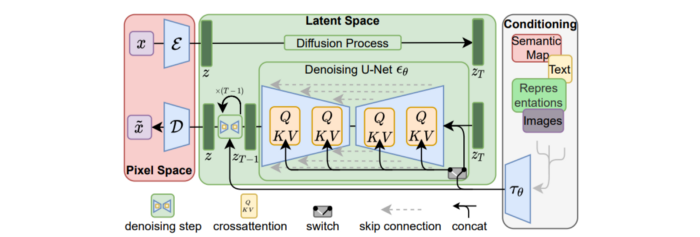
The weights file size for Stable Diffusion model v1 is 4 GB and v2 is 5 GB, making the model quite huge. The v1 model was trained on 256x256 and 512x512 LAION-5B pictures on a 4,000 GPU cluster using over 150.000 NVIDIA A100 GPU hours. The open-source pre-trained model is helpful for us. And we will.
Install
Before utilizing the Python sources for Stable Diffusion v1 on GitHub, we must install Miniconda (assuming Git and Python are already installed):
wget https://repo.anaconda.com/miniconda/Miniconda3-py39_4.12.0-Linux-x86_64.sh
chmod +x Miniconda3-py39_4.12.0-Linux-x86_64.sh
./Miniconda3-py39_4.12.0-Linux-x86_64.sh
conda update -n base -c defaults condaInstall the source and prepare the environment:
git clone https://github.com/CompVis/stable-diffusion
cd stable-diffusion
conda env create -f environment.yaml
conda activate ldm
pip3 install transformers --upgradeDownload the pre-trained model weights next. HiggingFace has the newest checkpoint sd-v14.ckpt (a download is free but registration is required). Put the file in the project folder and have fun:
python3 scripts/txt2img.py --prompt "hello world" --plms --ckpt sd-v1-4.ckpt --skip_grid --n_samples 1Almost. The installation is complete for happy users of current GPUs with 12 GB or more VRAM. RuntimeError: CUDA out of memory will occur otherwise. Two solutions exist.
Running the optimized version
Try optimizing first. After cloning the repository and enabling the environment (as previously), we can run the command:
python3 optimizedSD/optimized_txt2img.py --prompt "hello world" --ckpt sd-v1-4.ckpt --skip_grid --n_samples 1Stable Diffusion worked on my visual card with 8 GB RAM (alas, I did not behave well enough to get NVIDIA A100 for Christmas, so 8 GB GPU is the maximum I have;).
Running Stable Diffusion without GPU
If the GPU does not have enough RAM or is not CUDA-compatible, running the code on a CPU will be 20x slower but better than nothing. This unauthorized CPU-only branch from GitHub is easiest to obtain. We may easily edit the source code to use the latest version. It's strange that a pull request for that was made six months ago and still hasn't been approved, as the changes are simple. Readers can finish in 5 minutes:
Replace if attr.device!= torch.device(cuda) with if attr.device!= torch.device(cuda) and torch.cuda.is available at line 20 of ldm/models/diffusion/ddim.py ().
Replace if attr.device!= torch.device(cuda) with if attr.device!= torch.device(cuda) and torch.cuda.is available in line 20 of ldm/models/diffusion/plms.py ().
Replace device=cuda in lines 38, 55, 83, and 142 of ldm/modules/encoders/modules.py with device=cuda if torch.cuda.is available(), otherwise cpu.
Replace model.cuda() in scripts/txt2img.py line 28 and scripts/img2img.py line 43 with if torch.cuda.is available(): model.cuda ().
Run the script again.
Testing
Test the model. Text-to-image is the first choice. Test the command line example again:
python3 scripts/txt2img.py --prompt "hello world" --plms --ckpt sd-v1-4.ckpt --skip_grid --n_samples 1The slow generation takes 10 seconds on a GPU and 10 minutes on a CPU. Final image:

Hello world is dull and abstract. Try a brush-wielding hamster. Why? Because we can, and it's not as insane as Napoleon's cat. Another image:

Generating an image from a text prompt and another image is interesting. I made this picture in two minutes using the image editor (sorry, drawing wasn't my strong suit):
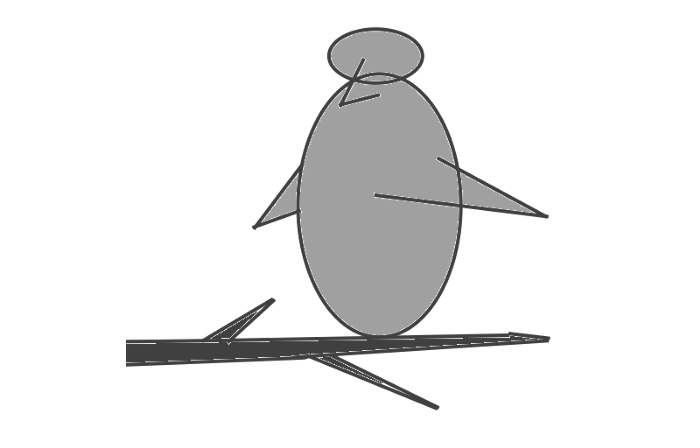
I can create an image from this drawing:
python3 scripts/img2img.py --prompt "A bird is sitting on a tree branch" --ckpt sd-v1-4.ckpt --init-img bird.png --strength 0.8It was far better than my initial drawing:

I hope readers understand and experiment.
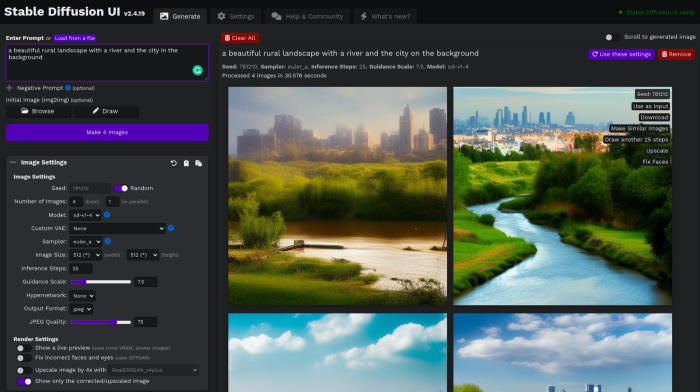
Stable Diffusion UI
Developers love the command line, but regular users may struggle. Stable Diffusion UI projects simplify image generation and installation. Simple usage:
Unpack the ZIP after downloading it from https://github.com/cmdr2/stable-diffusion-ui/releases. Linux and Windows are compatible with Stable Diffusion UI (sorry for Mac users, but those machines are not well-suitable for heavy machine learning tasks anyway;).
Start the script.
Done. The web browser UI makes configuring various Stable Diffusion features (upscaling, filtering, etc.) easy:
V2.1 of Stable Diffusion
I noticed the notification about releasing version 2.1 while writing this essay, and it was intriguing to test it. First, compare version 2 to version 1:
alternative text encoding. The Contrastive LanguageImage Pre-training (CLIP) deep learning model, which was trained on a significant number of text-image pairs, is used in Stable Diffusion 1. The open-source CLIP implementation used in Stable Diffusion 2 is called OpenCLIP. It is difficult to determine whether there have been any technical advancements or if legal concerns were the main focus. However, because the training datasets for the two text encoders were different, the output results from V1 and V2 will differ for the identical text prompts.
a new depth model that may be used to the output of image-to-image generation.
a revolutionary upscaling technique that can quadruple the resolution of an image.
Generally higher resolution Stable Diffusion 2 has the ability to produce both 512x512 and 768x768 pictures.
The Hugging Face website offers a free online demo of Stable Diffusion 2.1 for code testing. The process is the same as for version 1.4. Download a fresh version and activate the environment:
conda deactivate
conda env remove -n ldm # Use this if version 1 was previously installed
git clone https://github.com/Stability-AI/stablediffusion
cd stablediffusion
conda env create -f environment.yaml
conda activate ldmHugging Face offers a new weights ckpt file.
The Out of memory error prevented me from running this version on my 8 GB GPU. Version 2.1 fails on CPUs with the slow conv2d cpu not implemented for Half error (according to this GitHub issue, the CPU support for this algorithm and data type will not be added). The model can be modified from half to full precision (float16 instead of float32), however it doesn't make sense since v1 runs up to 10 minutes on the CPU and v2.1 should be much slower. The online demo results are visible. The same hamster painting with a brush prompt yielded this result:

It looks different from v1, but it functions and has a higher resolution.
The superresolution.py script can run the 4x Stable Diffusion upscaler locally (the x4-upscaler-ema.ckpt weights file should be in the same folder):
python3 scripts/gradio/superresolution.py configs/stable-diffusion/x4-upscaling.yaml x4-upscaler-ema.ckptThis code allows the web browser UI to select the image to upscale:
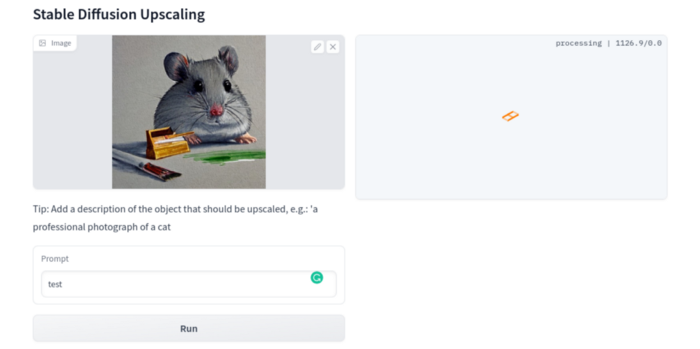
The copy-paste strategy may explain why the upscaler needs a text prompt (and the Hugging Face code snippet does not have any text input as well). I got a GPU out of memory error again, although CUDA can be disabled like v1. However, processing an image for more than two hours is unlikely:
Stable Diffusion Limitations
When we use the model, it's fun to see what it can and can't do. Generative models produce abstract visuals but not photorealistic ones. This fundamentally limits The generative neural network was trained on text and image pairs, but humans have a lot of background knowledge about the world. The neural network model knows nothing. If someone asks me to draw a Chinese text, I can draw something that looks like Chinese but is actually gibberish because I never learnt it. Generative AI does too! Humans can learn new languages, but the Stable Diffusion AI model includes only language and image decoder brain components. For instance, the Stable Diffusion model will pull NO WAR banner-bearers like this:
V1:

V2.1:

The shot shows text, although the model never learned to read or write. The model's string tokenizer automatically converts letters to lowercase before generating the image, so typing NO WAR banner or no war banner is the same.
I can also ask the model to draw a gorgeous woman:
V1:

V2.1:

The first image is gorgeous but physically incorrect. A second one is better, although it has an Uncanny valley feel. BTW, v2 has a lifehack to add a negative prompt and define what we don't want on the image. Readers might try adding horrible anatomy to the gorgeous woman request.
If we ask for a cartoon attractive woman, the results are nice, but accuracy doesn't matter:
V1:

V2.1:

Another example: I ordered a model to sketch a mouse, which looks beautiful but has too many legs, ears, and fingers:
V1:

V2.1: improved but not perfect.

V1 produces a fun cartoon flying mouse if I want something more abstract:

I tried multiple times with V2.1 but only received this:

The image is OK, but the first version is closer to the request.
Stable Diffusion struggles to draw letters, fingers, etc. However, abstract images yield interesting outcomes. A rural landscape with a modern metropolis in the background turned out well:
V1:

V2.1:

Generative models help make paintings too (at least, abstract ones). I searched Google Image Search for modern art painting to see works by real artists, and this was the first image:

I typed "abstract oil painting of people dancing" and got this:
V1:

V2.1:

It's a different style, but I don't think the AI-generated graphics are worse than the human-drawn ones.
The AI model cannot think like humans. It thinks nothing. A stable diffusion model is a billion-parameter matrix trained on millions of text-image pairs. I input "robot is creating a picture with a pen" to create an image for this post. Humans understand requests immediately. I tried Stable Diffusion multiple times and got this:

This great artwork has a pen, robot, and sketch, however it was not asked. Maybe it was because the tokenizer deleted is and a words from a statement, but I tried other requests such robot painting picture with pen without success. It's harder to prompt a model than a person.
I hope Stable Diffusion's general effects are evident. Despite its limitations, it can produce beautiful photographs in some settings. Readers who want to use Stable Diffusion results should be warned. Source code examination demonstrates that Stable Diffusion images feature a concealed watermark (text StableDiffusionV1 and SDV2) encoded using the invisible-watermark Python package. It's not a secret, because the official Stable Diffusion repository's test watermark.py file contains a decoding snippet. The put watermark line in the txt2img.py source code can be removed if desired. I didn't discover this watermark on photographs made by the online Hugging Face demo. Maybe I did something incorrectly (but maybe they are just not using the txt2img script on their backend at all).
Conclusion
The Stable Diffusion model was fascinating. As I mentioned before, trying something yourself is always better than taking someone else's word, so I encourage readers to do the same (including this article as well;).
Is Generative AI a game-changer? My humble experience tells me:
I think that place has a lot of potential. For designers and artists, generative AI can be a truly useful and innovative tool. Unfortunately, it can also pose a threat to some of them since if users can enter a text field to obtain a picture or a website logo in a matter of clicks, why would they pay more to a different party? Is it possible right now? unquestionably not yet. Images still have a very poor quality and are erroneous in minute details. And after viewing the image of the stunning woman above, models and fashion photographers may also unwind because it is highly unlikely that AI will replace them in the upcoming years.
Today, generative AI is still in its infancy. Even 768x768 images are considered to be of a high resolution when using neural networks, which are computationally highly expensive. There isn't an AI model that can generate high-resolution photographs natively without upscaling or other methods, at least not as of the time this article was written, but it will happen eventually.
It is still a challenge to accurately represent knowledge in neural networks (information like how many legs a cat has or the year Napoleon was born). Consequently, AI models struggle to create photorealistic photos, at least where little details are important (on the other side, when I searched Google for modern art paintings, the results are often even worse;).
When compared to the carefully chosen images from official web pages or YouTube reviews, the average output quality of a Stable Diffusion generation process is actually less attractive because to its high degree of randomness. When using the same technique on their own, consumers will theoretically only view those images as 1% of the results.
Anyway, it's exciting to witness this area's advancement, especially because the project is open source. Google's Imagen and DALL-E 2 can also produce remarkable findings. It will be interesting to see how they progress.