


G3nerative


Generative AI hype: some thoughts
The sudden surge in "generative AI" startups and projects feels like the inverse of the recent "web3" boom. Both came from hyped-up pots. But while web3 hyped idealistic tech and an easy way to make money, generative AI hypes unsettling tech and questions whether it can be used to make money.
Web3 is technology looking for problems to solve, while generative AI is technology creating almost too many solutions. Web3 has been evangelists trying to solve old problems with new technology. As Generative AI evolves, users are resolving old problems in stunning new ways.
It's a jab at web3, but it's true. Web3's hype, including crypto, was unhealthy. Always expected a tech crash and shakeout. Tech that won't look like "web3" but will enhance "web2"
But that doesn't mean AI hype is healthy. There'll be plenty of bullshit here, too. As moths to a flame, hype attracts charlatans. Again, the difference is the different starting point. People want to use it. Try it.
With the beta launch of Dall-E 2 earlier this year, a new class of consumer product took off. Midjourney followed suit (despite having to jump through the Discord server hoops). Twelve more generative art projects. Lensa, Prisma Labs' generative AI self-portrait project, may have topped the hype (a startup which has actually been going after this general space for quite a while). This week, ChatGPT went off-topic.
This has a "fake-it-till-you-make-it" vibe. We give these projects too much credit because they create easy illusions. This also unlocks new forms of creativity. And faith in new possibilities.
As a user, it's thrilling. We're just getting started. These projects are not only fun to play with, but each week brings a new breakthrough. As an investor, it's all happening so fast, with so much hype (and ethical and societal questions), that no one knows how it will turn out. Web3's demand won't be the issue. Too much demand may cause servers to melt down, sending costs soaring. Companies will try to mix rapidly evolving tech to meet user demand and create businesses. Frustratingly difficult.
Anyway, I wanted an excuse to post some Lensa selfies.
These are really weird. I recognize them as me or a version of me, but I have no memory of them being taken. It's surreal, out-of-body. Uncanny Valley.
More on Technology
James Brockbank
3 years ago • 7 min read
Canonical URLs for Beginners
Canonicalization and canonical URLs are essential for SEO, and improper implementation can negatively impact your site's performance.
Canonical tags were introduced in 2009 to help webmasters with duplicate or similar content on multiple URLs.
To use canonical tags properly, you must understand their purpose, operation, and implementation.
Canonical URLs and Tags
Canonical tags tell search engines that a certain URL is a page's master copy. They specify a page's canonical URL. Webmasters can avoid duplicate content by linking to the "canonical" or "preferred" version of a page.
How are canonical tags and URLs different? Can these be specified differently?
Tags
Canonical tags are found in an HTML page's head></head> section.
<link rel="canonical" href="https://www.website.com/page/" />These can be self-referencing or reference another page's URL to consolidate signals.
Canonical tags and URLs are often used interchangeably, which is incorrect.
The rel="canonical" tag is the most common way to set canonical URLs, but it's not the only way.
Canonical URLs
What's a canonical link? Canonical link is the'master' URL for duplicate pages.
In Google's own words:
A canonical URL is the page Google thinks is most representative of duplicate pages on your site.
— Google Search Console Help
You can indicate your preferred canonical URL. For various reasons, Google may choose a different page than you.
When set correctly, the canonical URL is usually your specified URL.
Canonical URLs determine which page will be shown in search results (unless a duplicate is explicitly better for a user, like a mobile version).
Canonical URLs can be on different domains.
Other ways to specify canonical URLs
Canonical tags are the most common way to specify a canonical URL.
You can also set canonicals by:
Setting the HTTP header rel=canonical.
All pages listed in a sitemap are suggested as canonicals, but Google decides which pages are duplicates.
Redirects 301.
Google recommends these methods, but they aren't all appropriate for every situation, as we'll see below. Each has its own recommended uses.
Setting canonical URLs isn't required; if you don't, Google will use other signals to determine the best page version.
To control how your site appears in search engines and to avoid duplicate content issues, you should use canonicalization effectively.
Why Duplicate Content Exists
Before we discuss why you should use canonical URLs and how to specify them in popular CMSs, we must first explain why duplicate content exists. Nobody intentionally duplicates website content.
Content management systems create multiple URLs when you launch a page, have indexable versions of your site, or use dynamic URLs.
Assume the following URLs display the same content to a user:
A search engine sees eight duplicate pages, not one.
URLs #1 and #2: the CMS saves product URLs with and without the category name.
#3, #4, and #5 result from the site being accessible via HTTP, HTTPS, www, and non-www.
#6 is a subdomain mobile-friendly URL.
URL #7 lacks URL #2's trailing slash.
URL #8 uses a capital "A" instead of a lowercase one.
Duplicate content may also exist in URLs like:
https://www.website.com
https://www.website.com/index.php
Duplicate content is easy to create.
Canonical URLs help search engines identify different page variations as a single URL on many sites.
SEO Canonical URLs
Canonical URLs help you manage duplicate content that could affect site performance.
Canonical URLs are a technical SEO focus area for many reasons.
Specify URL for search results
When you set a canonical URL, you tell Google which page version to display.
Which would you click?
https://www.domain.com/page-1/
https://www.domain.com/index.php?id=2
First, probably.
Canonicals tell search engines which URL to rank.
Consolidate link signals on similar pages
When you have duplicate or nearly identical pages on your site, the URLs may get external links.
Canonical URLs consolidate multiple pages' link signals into a single URL.
This helps your site rank because signals from multiple URLs are consolidated into one.
Syndication management
Content is often syndicated to reach new audiences.
Canonical URLs consolidate ranking signals to prevent duplicate pages from ranking and ensure the original content ranks.
Avoid Googlebot duplicate page crawling
Canonical URLs ensure that Googlebot crawls your new pages rather than duplicated versions of the same one across mobile and desktop versions, for example.
Crawl budgets aren't an issue for most sites unless they have 100,000+ pages.
How to Correctly Implement the rel=canonical Tag
Using the header tag rel="canonical" is the most common way to specify canonical URLs.
Adding tags and HTML code may seem daunting if you're not a developer, but most CMS platforms allow canonicals out-of-the-box.
These URLs each have one product.
How to Correctly Implement a rel="canonical" HTTP Header
A rel="canonical" HTTP header can replace canonical tags.
This is how to implement a canonical URL for PDFs or non-HTML documents.
You can specify a canonical URL in your site's.htaccess file using the code below.
<Files "file-to-canonicalize.pdf"> Header add Link "< http://www.website.com/canonical-page/>; rel=\"canonical\"" </Files>301 redirects for canonical URLs
Google says 301 redirects can specify canonical URLs.
Only the canonical URL will exist if you use 301 redirects. This will redirect duplicates.
This is the best way to fix duplicate content across:
HTTPS and HTTP
Non-WWW and WWW
Trailing-Slash and Non-Trailing Slash URLs
On a single page, you should use canonical tags unless you can confidently delete and redirect the page.
Sitemaps' canonical URLs
Google assumes sitemap URLs are canonical, so don't include non-canonical URLs.
This does not guarantee canonical URLs, but is a best practice for sitemaps.
Best-practice Canonical Tag
Once you understand a few simple best practices for canonical tags, spotting and cleaning up duplicate content becomes much easier.
Always include:
One canonical URL per page
If you specify multiple canonical URLs per page, they will likely be ignored.
Correct Domain Protocol
If your site uses HTTPS, use this as the canonical URL. It's easy to reference the wrong protocol, so check for it to catch it early.
Trailing slash or non-trailing slash URLs
Be sure to include trailing slashes in your canonical URL if your site uses them.
Specify URLs other than WWW
Search engines see non-WWW and WWW URLs as duplicate pages, so use the correct one.
Absolute URLs
To ensure proper interpretation, canonical tags should use absolute URLs.
So use:
<link rel="canonical" href="https://www.website.com/page-a/" />And not:
<link rel="canonical" href="/page-a/" />If not canonicalizing, use self-referential canonical URLs.
When a page isn't canonicalizing to another URL, use self-referencing canonical URLs.
Canonical tags refer to themselves here.
Common Canonical Tags Mistakes
Here are some common canonical tag mistakes.
301 Canonicalization
Set the canonical URL as the redirect target, not a redirected URL.
Incorrect Domain Canonicalization
If your site uses HTTPS, don't set canonical URLs to HTTP.
Irrelevant Canonicalization
Canonicalize URLs to duplicate or near-identical content only.
SEOs sometimes try to pass link signals via canonical tags from unrelated content to increase rank. This isn't how canonicalization should be used and should be avoided.
Multiple Canonical URLs
Only use one canonical tag or URL per page; otherwise, they may all be ignored.
When overriding defaults in some CMSs, you may accidentally include two canonical tags in your page's <head>.
Pagination vs. Canonicalization
Incorrect pagination can cause duplicate content. Canonicalizing URLs to the first page isn't always the best solution.
Canonicalize to a 'view all' page.
How to Audit Canonical Tags (and Fix Issues)
Audit your site's canonical tags to find canonicalization issues.
SEMrush Site Audit can help. You'll find canonical tag checks in your website's site audit report.
Let's examine these issues and their solutions.
No Canonical Tag on AMP
Site Audit will flag AMP pages without canonical tags.
Canonicalization between AMP and non-AMP pages is important.
Add a rel="canonical" tag to each AMP page's head>.
No HTTPS redirect or canonical from HTTP homepage
Duplicate content issues will be flagged in the Site Audit if your site is accessible via HTTPS and HTTP.
You can fix this by 301 redirecting or adding a canonical tag to HTTP pages that references HTTPS.
Broken canonical links
Broken canonical links won't be considered canonical URLs.
This error could mean your canonical links point to non-existent pages, complicating crawling and indexing.
Update broken canonical links to the correct URLs.
Multiple canonical URLs
This error occurs when a page has multiple canonical URLs.
Remove duplicate tags and leave one.
Canonicalization is a key SEO concept, and using it incorrectly can hurt your site's performance.
Once you understand how it works, what it does, and how to find and fix issues, you can use it effectively to remove duplicate content from your site.
Canonicalization SEO Myths
Monroe Mayfield
2 years ago • 2 min read
CES 2023: A Third Look At Upcoming Trends
Las Vegas hosted CES 2023. This third and last look at CES 2023 previews upcoming consumer electronics trends that will be crucial for market share.

Definitely start with ICT. Qualcomm CEO Cristiano Amon spoke to CNBC from Las Vegas on China's crackdown and the company's automated driving systems for electric vehicles (EV). The business showed a concept car and its latest Snapdragon processor designs, which offer expanded digital interactions through SalesForce-partnered CRM platforms.
Electrification is reviving Michigan's automobile industry. Michigan Local News reports that $14 billion in EV and battery manufacturing investments will benefit the state. The report also revealed that the Strategic Outreach and Attraction Reserve (SOAR) fund had generated roughly $1 billion for the state's automotive sector.
Ars Technica is great for technology, society, and the future. After CES 2023, Jonathan M. Gitlin published How many electric car chargers are enough? Read about EV charging network issues and infrastructure spending. Politics aside, rapid technological advances enable EV charging network expansion in American cities and abroad.
Finally, the UNEP's The Future of Electric Vehicles and Material Resources: A Foresight Brief. Understanding how lithium-ion batteries will affect EV sales is crucial. Climate change affects EVs in various ways, but electrification and mining trends stand out because more EVs demand more energy-intensive metals and rare earths. Areas & Producers has been publishing my electrification and mining trends articles. Follow me if you wish to write for the publication.
The Weekend Brief (TWB) will routinely cover tech, industrials, and global commodities in global markets, including stock markets. Read more about the future of key areas and critical producers of the global economy in Areas & Producers.

The Mystique
2 years ago • 4 min read
Four Shocking Dark Web Incidents that Should Make You Avoid It
Dark Web activity? Is it as horrible as they say?

We peruse our phones for hours. Internet has improved our worldview.
However, the world's harshest realities remain buried on the internet and unattainable by everyone.
Browsers cannot access the Dark Web. Browse it with high-security authentication and exclusive access. There are compelling reasons to avoid the dark web at all costs.
1. The Dark Web and I

Darius wrote My Dark Web Story on reddit two years ago. The user claimed to have shared his dark web experience. DaRealEddyYT wanted to surf the dark web after hearing several stories.
He curiously downloaded Tor Browser, which provides anonymity and security.
In the Dark Room, bound
As Darius logged in, a text popped up: “Want a surprise? Click on this link.”
The link opened to a room with a chair. Only one light source illuminated the room. The chair held a female tied.
As the screen read "Let the game begin," a man entered the room and was paid in bitcoins to torment the girl.
The man dragged and tortured the woman.
A danger to safety
Leaving so soon, Darius, disgusted Darius tried to leave the stream. The anonymous user then sent Darius his personal information, including his address, which frightened him because he didn't know Tor was insecure.
After deleting the app, his phone camera was compromised.
He also stated that he left his residence and returned to find it unlocked and a letter saying, Thought we wouldn't find you? Reddit never updated the story.
The story may have been a fake, but a much scarier true story about the dark side of the internet exists.
2. The Silk Road Market

The dark web is restricted for a reason. The dark web has everything illicit imaginable. It's awful central.
The dark web has everything, from organ sales to drug trafficking to money laundering to human trafficking. Illegal drugs, pirated software, credit card, bank, and personal information can be found in seconds.
The dark web has reserved websites like Google. The Silk Road Website, which operated from 2011 to 2013, was a leading digital black market.
The FBI grew obsessed with site founder and processor Ross William Ulbricht.
The site became a criminal organization as money laundering and black enterprises increased. Bitcoin was utilized for credit card payment.
The FBI was close to arresting the site's administrator. Ross was detained after the agency closed Silk Road in 2013.
Two years later, in 2015, he was convicted and sentenced to two consecutive life terms and forty years. He appealed in 2016 but was denied, thus he is currently serving time.
The hefty sentence was for more than running a black marketing site. He was also convicted of murder-for-hire, earning about $730,000 in a short time.
3. Person-buying auctions

Bidding on individuals is another weird internet activity. After a Milan photo shoot, 20-year-old British model Chloe Ayling was kidnapped.
An ad agency in Milan made a bogus offer to shoot with the mother of a two-year-old boy. Four men gave her anesthetic and put her in a duffel bag when she arrived.
She was held captive for several days, and her images and $300,000 price were posted on the dark web. Black Death Trafficking Group kidnapped her to sell her for sex.
She was told two black death foot warriors abducted her. The captors released her when they found she was a mother because mothers were less desirable to sex slave buyers.
In July 2018, Lukasz Pawel Herba was arrested and sentenced to 16 years and nine months in prison. Being a young mother saved Chloe from creepy bidding.
However, it exceeds expectations of how many more would be in such danger daily without their knowledge.
4. Organ sales

Many are unaware of dark web organ sales. Patients who cannot acquire organs often turn to dark web brokers.
Brokers handle all transactions between donors and customers.
Bitcoins are used for dark web transactions, and the Tor server permits personal data on the web.
The WHO reports approximately 10,000 unlawful organ transplants annually. The black web sells kidneys, hearts, even eyes.
To protect our lives and privacy, we should manage our curiosity and never look up dangerous stuff.
While it's fascinating and appealing to know what's going on in the world we don't know about, it's best to prioritize our well-being because one never knows how bad it might get.
Sources
You might also like

nft now
3 years ago • 5 min read
A Guide to VeeFriends and Series 2
VeeFriends is one of the most popular and unique NFT collections. VeeFriends launched around the same time as other PFP NFTs like Bored Ape Yacht Club.
Vaynerchuk (GaryVee) took a unique approach to his large-scale project, which has influenced the NFT ecosystem. GaryVee's VeeFriends is one of the most successful NFT membership use-cases, allowing him to build a community around his creative and business passions.
What is VeeFriends?
GaryVee's NFT collection, VeeFriends, was released on May 11, 2021. VeeFriends [Mini Drops], Book Games, and a forthcoming large-scale "Series 2" collection all stem from the initial drop of 10,255 tokens.
In "Series 1," there are G.O.O. tokens (Gary Originally Owned). GaryVee reserved 1,242 NFTs (over 12% of the supply) for his own collection, so only 9,013 were available at the Series 1 launch.
Each Series 1 token represents one of 268 human traits hand-drawn by Vaynerchuk. Gary Vee's NFTs offer owners incentives.
Who made VeeFriends?
Gary Vaynerchuk, AKA GaryVee, is influential in NFT. Vaynerchuk is the chairman of New York-based communications company VaynerX. Gary Vee, CEO of VaynerMedia, VaynerSports, and bestselling author, is worth $200 million.
GaryVee went from NFT collector to creator, launching VaynerNFT to help celebrities and brands.
Vaynerchuk's influence spans the NFT ecosystem as one of its most prolific voices. He's one of the most influential NFT figures, and his VeeFriends ecosystem keeps growing.
Vaynerchuk, a trend expert, thinks NFTs will be around for the rest of his life and VeeFriends will be a landmark project.
Why use VeeFriends NFTs?
The first VeeFriends collection has sold nearly $160 million via OpenSea. GaryVee insisted that the first 10,255 VeeFriends were just the beginning.
Book Games were announced to the VeeFriends community in August 2021. Mini Drops joined VeeFriends two months later.
Book Games
GaryVee's book "Twelve and a Half: Leveraging the Emotional Ingredients for Business Success" inspired Book Games. Even prior to the announcement Vaynerchuk had mapped out the utility of the book on an NFT scale. Book Games tied his book to the VeeFriends ecosystem and solidified its place in the collection.
GaryVee says Book Games is a layer 2 NFT project with 125,000 burnable tokens. Vaynerchuk's NFT fans were incentivized to buy as many copies of his new book as possible to receive NFT rewards later.
First, a bit about “layer 2.”
Layer 2 blockchain solutions help scale applications by routing transactions away from Ethereum Mainnet (layer 1). These solutions benefit from Mainnet's decentralized security model but increase transaction speed and reduce gas fees.
Polygon (integrated into OpenSea) and Immutable X are popular Ethereum layer 2 solutions. GaryVee chose Immutable X to reduce gas costs (transaction fees). Given the large supply of Book Games tokens, this decision will likely benefit the VeeFriends community, especially if the games run forever.
What's the strategy?
The VeeFriends patriarch announced on Aug. 27, 2021, that for every 12 books ordered during the Book Games promotion, customers would receive one NFT via airdrop. After nearly 100 days, GV sold over a million copies and announced that Book Games would go gamified on Jan. 10, 2022.
Immutable X's trading options make Book Games a "game." Book Games players can trade NFTs for other NFTs, sports cards, VeeCon tickets, and other prizes. Book Games can also whitelist other VeeFirends projects, which we'll cover in Series 2.
VeeFriends Mini Drops
GaryVee launched VeeFriends Mini Drops two months after Book Games, focusing on collaboration, scarcity, and the characters' "cultural longevity."
Spooky Vees, a collection of 31 1/1 Halloween-themed VeeFriends, was released on Halloween. First-come, first-served VeeFriend owners could claim these NFTs.
Mini Drops includes Gift Goat NFTs. By holding the Gift Goat VeeFriends character, collectors will receive 18 exclusive gifts curated by GaryVee and the team. Each gifting experience includes one physical gift and one NFT out of 555, to match the 555 Gift Goat tokens.
Gift Goat holders have gotten NFTs from Danny Cole (Creature World), Isaac "Drift" Wright (Where My Vans Go), Pop Wonder, and more.
GaryVee is poised to release the largest expansion of the VeeFriends and VaynerNFT ecosystem to date with VeeFriends Series 2.
VeeCon 101
By owning VeeFriends NFTs, collectors can join the VeeFriends community and attend VeeCon in 2022. The conference is only open to VeeCon NFT ticket holders (VeeFreinds + possibly more TBA) and will feature Beeple, Steve Aoki, and even Snoop Dogg.
The VeeFreinds floor in 2022 Q1 has remained at 16 ETH ($52,000), making VeeCon unattainable for most NFT enthusiasts. Why would someone spend that much crypto on a Minneapolis "superconference" ticket? Because of Gary Vaynerchuk.
Everything to know about VeeFriends Series 2
Vaynerchuk revealed in April 2022 that the VeeFriends ecosystem will grow by 55,555 NFTs after months of teasing.
With VeeFriends Series 2, each token will cost $995 USD in ETH, allowing NFT enthusiasts to join at a lower cost. The new series will be released on multiple dates in April.
Book Games NFT holders on the Friends List (whitelist) can mint Series 2 NFTs on April 12. Book Games holders have 32,000 NFTs.
VeeFriends Series 1 NFT holders can claim Series 2 NFTs on April 12. This allotment's supply is 10,255, like Series 1's.
On April 25, the public can buy 10,000 Series 2 NFTs. Unminted Friends List NFTs will be sold on this date, so this number may change.
The VeeFriends ecosystem will add 15 new characters (220 tokens each) on April 27. One character will be released per day for 15 days, and the only way to get one is to enter a daily raffle with Book Games tokens.
Series 2 NFTs won't give owners VeeCon access, but they will offer other benefits within the VaynerNFT ecosystem. Book Games and Series 2 will get new token burn mechanics in the upcoming drop.
Visit the VeeFriends blog for the latest collection info.
Where can you buy Gary Vee’s NFTs?
Need a VeeFriend NFT? Gary Vee recommends doing "50 hours of homework" before buying. OpenSea sells VeeFriends NFTs.

Matthew Cluff
2 years ago • 11 min read
GTO Poker 101
"GTO" (Game Theory Optimal) has been used a lot in poker recently. To clarify its meaning and application, the aim of this article is to define what it is, when to use it when playing, what strategies to apply for how to play GTO poker, for beginner and more advanced players!
Poker GTO
In poker, you can choose between two main winning strategies:
Exploitative play maximizes expected value (EV) by countering opponents' sub-optimal plays and weaker tendencies. Yes, playing this way opens you up to being exploited, but the weaker opponents you're targeting won't change their game to counteract this, allowing you to reap maximum profits over the long run.
GTO (Game-Theory Optimal): You try to play perfect poker, which forces your opponents to make mistakes (which is where almost all of your profit will be derived from). It mixes bluffs or semi-bluffs with value bets, clarifies bet sizes, and more.
GTO vs. Exploitative: Which is Better in Poker?
Before diving into GTO poker strategy, it's important to know which of these two play styles is more profitable for beginners and advanced players. The simple answer is probably both, but usually more exploitable.
Most players don't play GTO poker and can be exploited in their gameplay and strategy, allowing for more profits to be made using an exploitative approach. In fact, it’s only in some of the largest games at the highest stakes that GTO concepts are fully utilized and seen in practice, and even then, exploitative plays are still sometimes used.
Knowing, understanding, and applying GTO poker basics will create a solid foundation for your poker game. It's also important to understand GTO so you can deviate from it to maximize profits.
GTO Poker Strategy
According to Ed Miller's book "Poker's 1%," the most fundamental concept that only elite poker players understand is frequency, which could be in relation to cbets, bluffs, folds, calls, raises, etc.
GTO poker solvers (downloadable online software) give solutions for how to play optimally in any given spot and often recommend using mixed strategies based on select frequencies.
In a river situation, a solver may tell you to call 70% of the time and fold 30%. It may also suggest calling 50% of the time, folding 35% of the time, and raising 15% of the time (with a certain range of hands).
Frequencies are a fundamental and often unrecognized part of poker, but they run through these 5 GTO concepts.
1. Preflop ranges
To compensate for positional disadvantage, out-of-position players must open tighter hand ranges.
Premium starting hands aren't enough, though. Considering GTO poker ranges and principles, you want a good, balanced starting hand range from each position with at least some hands that can make a strong poker hand regardless of the flop texture (low, mid, high, disconnected, etc).
Below is a GTO preflop beginner poker chart for online 6-max play, showing which hand ranges one should open-raise with. Table positions are color-coded (see key below).
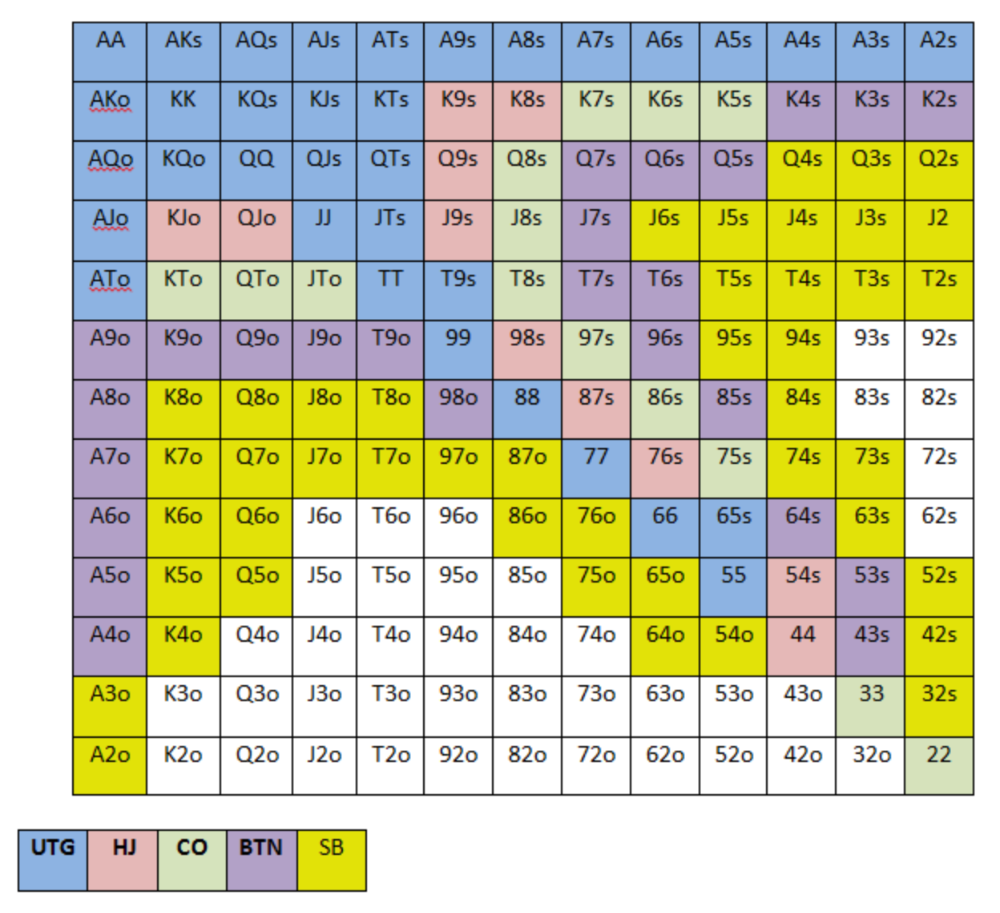
NOTE: For GTO play, it's advisable to use a mixed strategy for opening in the small blind, combining open-limps and open-raises for various hands. This cannot be illustrated with the color system used for the chart.
Choosing which hands to play is often a math problem, as discussed below.
Other preflop GTO poker charts include which hands to play after a raise, which to 3bet, etc. Solvers can help you decide which preflop hands to play (call, raise, re-raise, etc.).
2. Pot Odds
Always make +EV decisions that profit you as a poker player. Understanding pot odds (and equity) can help.
Postflop Pot Odds
Let’s say that we have JhTh on a board of 9h8h2s4c (open-ended straight-flush draw). We have $40 left and $50 in the pot. He has you covered and goes all-in. As calling or folding are our only options, playing GTO involves calculating whether a call is +EV or –EV. (The hand was empty.)
Any remaining heart, Queen, or 7 wins the hand. This means we can improve 15 of 46 unknown cards, or 32.6% of the time.
What if our opponent has a set? The 4h or 2h could give us a flush, but it could also give the villain a boat. If we reduce outs from 15 to 14.5, our equity would be 31.5%.
We must now calculate pot odds.
(bet/(our bet+pot)) = pot odds
= $50 / ($40 + $90)
= $40 / $130
= 30.7%
To make a profitable call, we need at least 30.7% equity. This is a profitable call as we have 31.5% equity (even if villain has a set). Yes, we will lose most of the time, but we will make a small profit in the long run, making a call correct.
Pot odds aren't just for draws, either. If an opponent bets 50% pot, you get 3 to 1 odds on a call, so you must win 25% of the time to be profitable. If your current hand has more than 25% equity against your opponent's perceived range, call.
Preflop Pot Odds
Preflop, you raise to 3bb and the button 3bets to 9bb. You must decide how to act. In situations like these, we can actually use pot odds to assist our decision-making.
This pot is:
(our open+3bet size+small blind+big blind)
(3bb+9bb+0.5bb+1bb)
= 13.5
This means we must call 6bb to win a pot of 13.5bb, which requires 30.7% equity against the 3bettor's range.
Three additional factors must be considered:
Being out of position on our opponent makes it harder to realize our hand's equity, as he can use his position to put us in tough spots. To profitably continue against villain's hand range, we should add 7% to our equity.
Implied Odds / Reverse Implied Odds: The ability to win or lose significantly more post-flop (than pre-flop) based on our remaining stack.
While statistics on 3bet stats can be gained with a large enough sample size (i.e. 8% 3bet stat from button), the numbers don't tell us which 8% of hands villain could be 3betting with. Both polarized and depolarized charts below show 8% of possible hands.
7.4% of hands are depolarized.
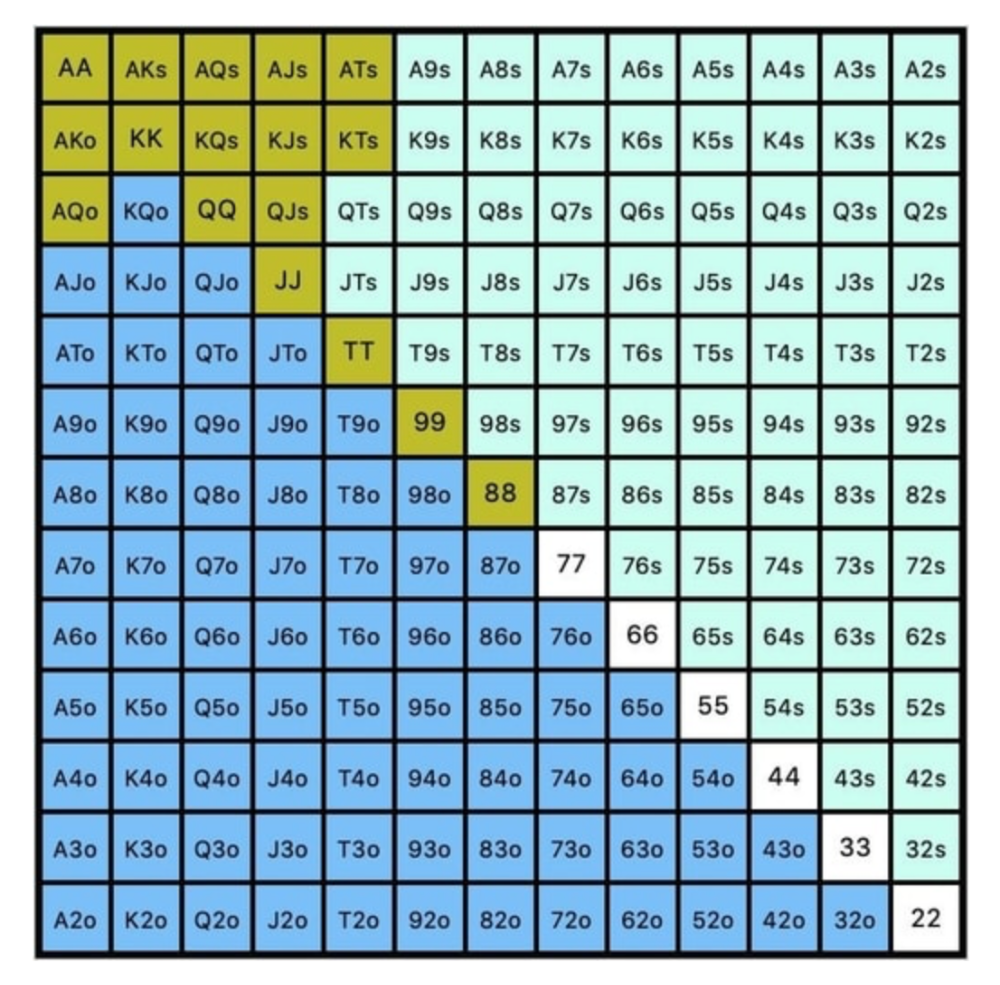
Polarized Hand range (7.54%):
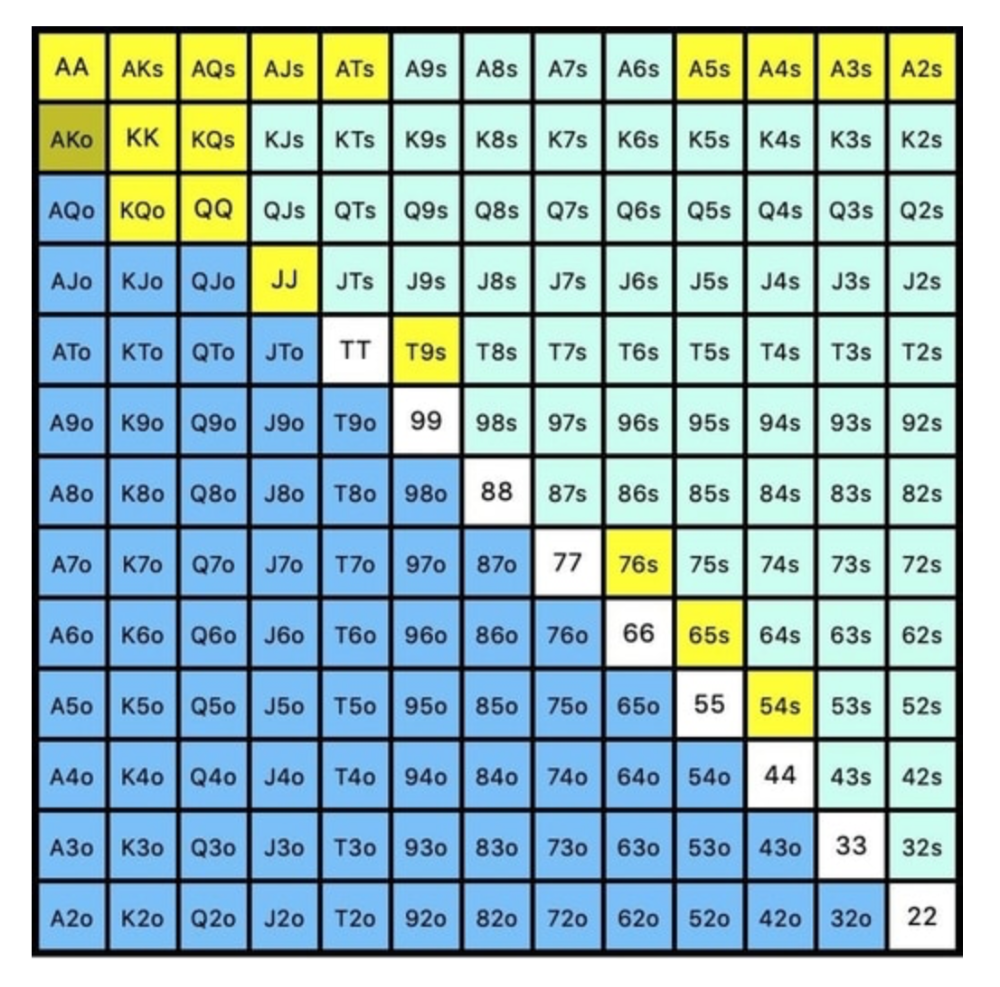
Each hand range has different contents. We don't know if he 3bets some hands and calls or folds others.
Using an exploitable strategy can help you play a hand range correctly. The next GTO concept will make things easier.
3. Minimum Defense Frequency:
This concept refers to the % of our range we must continue with (by calling or raising) to avoid being exploited by our opponents. This concept is most often used off-table and is difficult to apply in-game.
These beginner GTO concepts will help your decision-making during a hand, especially against aggressive opponents.
MDF formula:
MDF = POT SIZE/(POT SIZE+BET SIZE)
Here's a poker GTO chart of common bet sizes and minimum defense frequency.
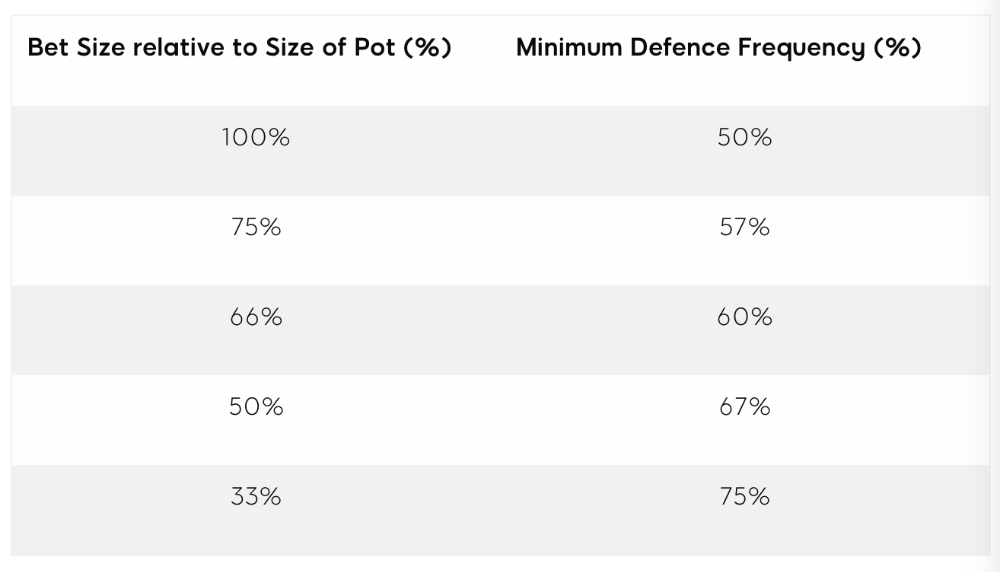
Take the number of hand combos in your starting hand range and use the MDF to determine which hands to continue with. Choose hands with the most playability and equity against your opponent's betting range.
Say you open-raise HJ and BB calls. Qh9h6c flop. Your opponent leads you for a half-pot bet. MDF suggests keeping 67% of our range.
Using the above starting hand chart, we can determine that the HJ opens 254 combos:
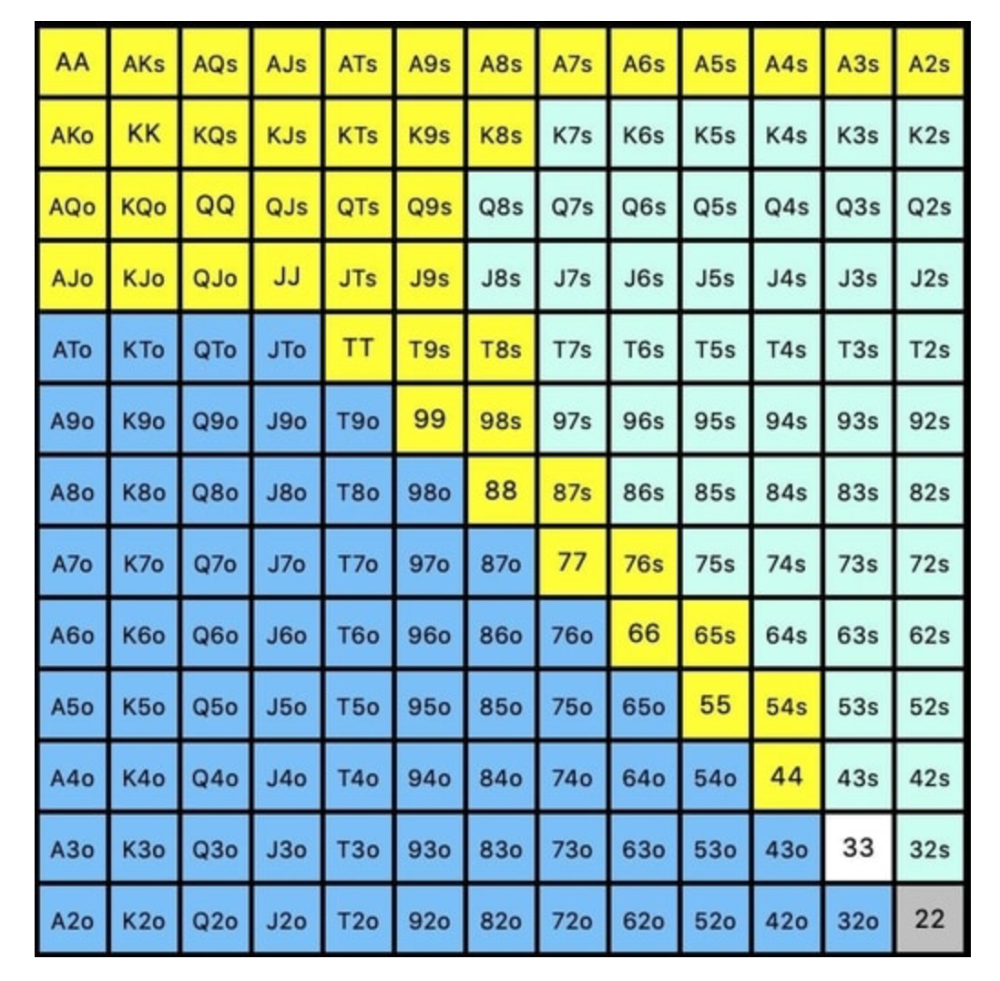
We must defend 67% of these hands, or 170 combos, according to MDF. Hands we should keep include:
Flush draws
Open-Ended Straight Draws
Gut-Shot Straight Draws
Overcards
Any Pair or better
So, our flop continuing range could be:
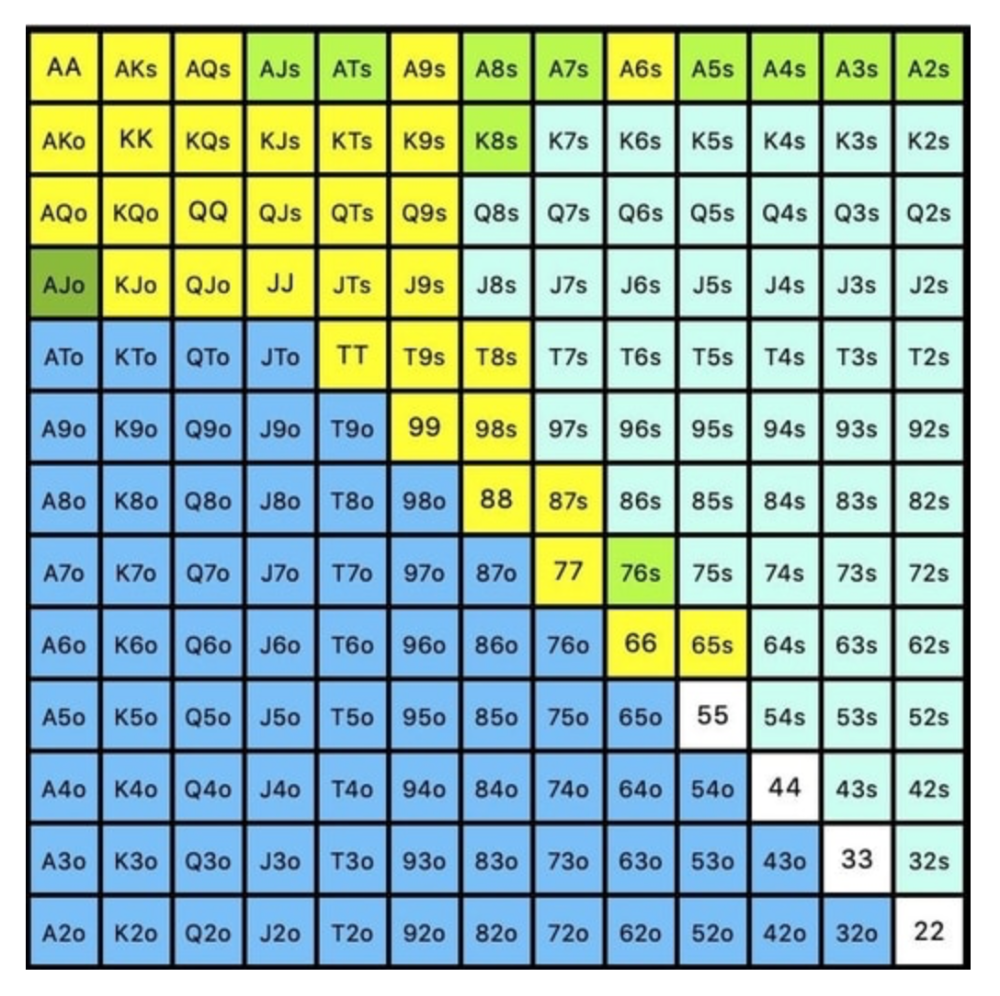
Some highlights:
Fours and fives have little chance of improving on the turn or river.
We only continue with AX hearts (with a flush draw) without a pair or better.
We'll also include 4 AJo combos, all of which have the Ace of hearts, and AcJh, which can block a backdoor nut flush combo.
Let's assume all these hands are called and the turn is blank (2 of spades). Opponent bets full-pot. MDF says we must defend 50% of our flop continuing range, or 85 of 170 combos, to be unexploitable. This strategy includes our best flush draws, straight draws, and made hands.
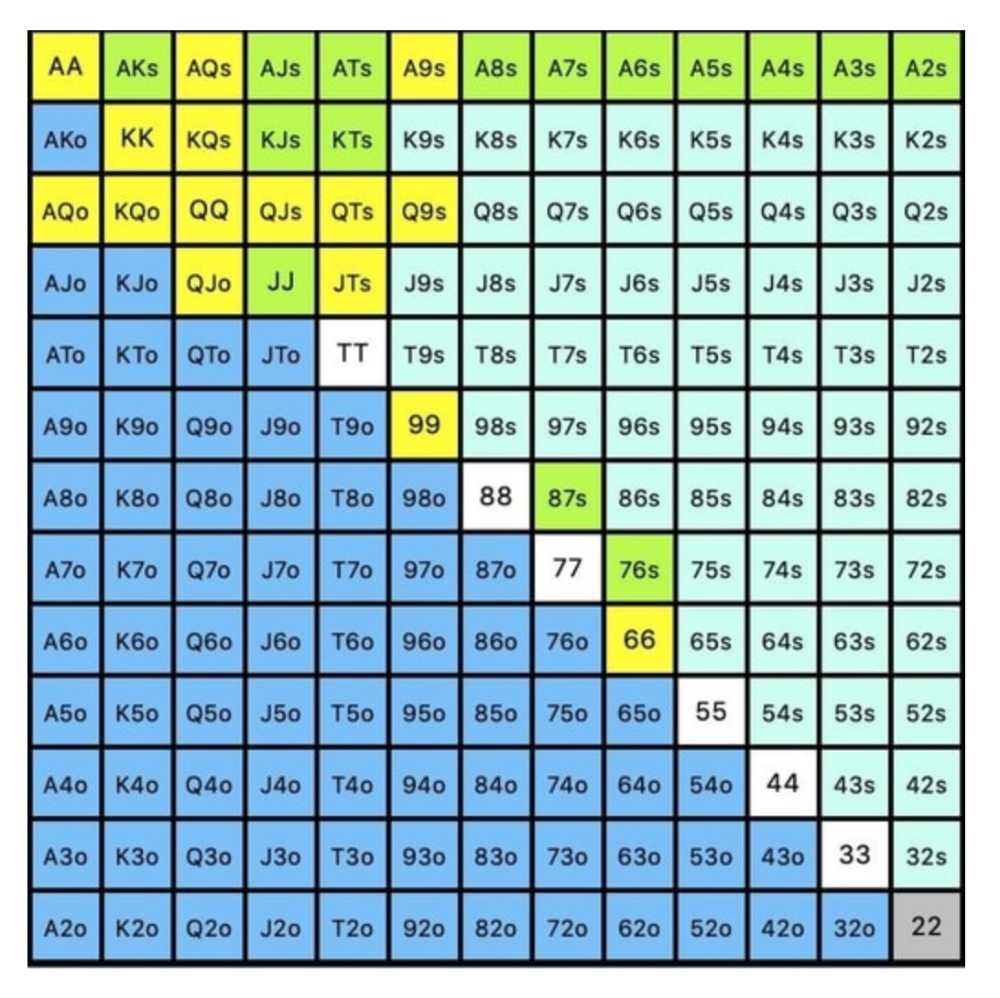
Here, we keep combining:
Nut flush draws
Pair + flush draws
GS + flush draws
Second Pair, Top Kicker+
One combo of JJ that doesn’t block the flush draw or backdoor flush draw.
On the river, we can fold our missed draws and keep our best made hands. When calling with weaker hands, consider blocker effects and card removal to avoid overcalling and decide which combos to continue.
4. Poker GTO Bet Sizing
To avoid being exploited, balance your bluffs and value bets. Your betting range depends on how much you bet (in relation to the pot). This concept only applies on the river, as draws (bluffs) on the flop and turn still have equity (and are therefore total bluffs).
On the flop, you want a 2:1 bluff-to-value-bet ratio. On the flop, there won't be as many made hands as on the river, and your bluffs will usually contain equity. The turn should have a "bluffing" ratio of 1:1. Use the chart below to determine GTO river bluff frequencies (relative to your bet size):
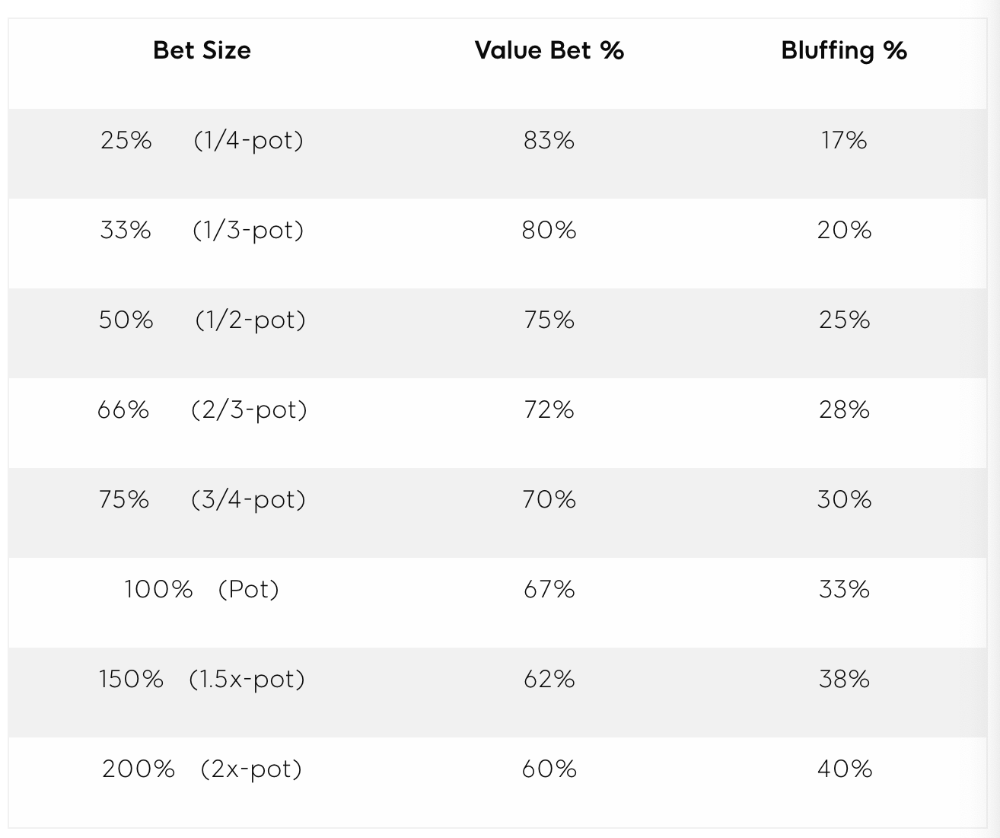
This chart relates to your opponent's pot odds. If you bet 50% pot, your opponent gets 3:1 odds and must win 25% of the time to call. Poker GTO theory suggests including 25% bluff combinations in your betting range so you're indifferent to your opponent calling or folding.
Best river bluffs don't block hands you want your opponent to have (or not have). For example, betting with missed Ace-high flush draws is often a mistake because you block a missed flush draw you want your opponent to have when bluffing on the river (meaning that it would subsequently be less likely he would have it, if you held two of the flush draw cards). Ace-high usually has some river showdown value.
If you had a 3-flush on the river and wanted to raise, you could bluff raise with AX combos holding the bluff suit Ace. Blocking the nut flush prevents your opponent from using that combo.
5. Bet Sizes and Frequency
GTO beginner strategies aren't just bluffs and value bets. They show how often and how much to bet in certain spots. Top players have benefited greatly from poker solvers, which we'll discuss next.
GTO Poker Software
In recent years, various poker GTO solvers have been released to help beginner, intermediate, and advanced players play balanced/GTO poker in various situations.
PokerSnowie and PioSolver are popular GTO and poker study programs.
While you can't compute players' hand ranges and what hands to bet or check with in real time, studying GTO play strategies with these programs will pay off. It will improve your poker thinking and understanding.
Solvers can help you balance ranges, choose optimal bet sizes, and master cbet frequencies.
GTO Poker Tournament
Late-stage tournaments have shorter stacks than cash games. In order to follow GTO poker guidelines, Nash charts have been created, tweaked, and used for many years (and also when to call, depending on what number of big blinds you have when you find yourself shortstacked).
The charts are for heads-up push/fold. In a multi-player game, the "pusher" chart can only be used if play is folded to you in the small blind. The "caller" chart can only be used if you're in the big blind and assumes a small blind "pusher" (with a much wider range than if a player in another position was open-shoving).
Divide the pusher chart's numbers by 2 to see which hand to use from the Button. Divide the original chart numbers by 4 to find the CO's pushing range. Some of the figures will be impossible to calculate accurately for the CO or positions to the right of the blinds because the chart's highest figure is "20+" big blinds, which is also used for a wide range of hands in the push chart.
Both of the GTO charts below are ideal for heads-up play, but exploitable HU shortstack strategies can lead to more +EV decisions against certain opponents. Following the charts will make your play GTO and unexploitable.
Poker pro Max Silver created the GTO push/fold software SnapShove. (It's accessible online at www.snapshove.com or as iOS or Android apps.)
Players can access GTO shove range examples in the full version. (You can customize the number of big blinds you have, your position, the size of the ante, and many other options.)
In Conclusion
Due to the constantly changing poker landscape, players are always improving their skills. Exploitable strategies often yield higher profit margins than GTO-based approaches, but knowing GTO beginner and advanced concepts can give you an edge for a few reasons.
It creates a solid gameplay base.
Having a baseline makes it easier to exploit certain villains.
You can avoid leveling wars with your opponents by making sound poker decisions based on GTO strategy.
It doesn't require assuming opponents' play styles.
Not results-oriented.
This is just the beginning of GTO and poker theory. Consider investing in the GTO poker solver software listed above to improve your game.

Luke Plunkett
3 years ago • 2 min read
Gran Turismo 7 Update Eases Up On The Grind After Fan Outrage
Polyphony Digital has changed the game after apologizing in March.
To make amends for some disastrous downtime, Gran Turismo 7 director Kazunori Yamauchi announced a credits handout and promised to “dramatically change GT7's car economy to help make amends” last month. The first of these has arrived.
The game's 1.11 update includes the following concessions to players frustrated by the economy and its subsequent grind:
-
The last half of the World Circuits events have increased in-game credit rewards.
-
Modified Arcade and Custom Race rewards
-
Clearing all circuit layouts with Gold or Bronze now rewards In-game Credits. Exiting the Sector selection screen with the Exit button will award Credits if an event has already been cleared.
-
Increased Credits Rewards in Lobby and Daily Races
-
Increased the free in-game Credits cap from 20,000,000 to 100,000,000.
Additionally, “The Human Comedy” missions are one-hour endurance races that award “up to 1,200,000” credits per event.
This isn't everything Yamauchi promised last month; he said it would take several patches and updates to fully implement the changes. Here's a list of everything he said would happen, some of which have already happened (like the World Cup rewards and credit cap):
- Increase rewards in the latter half of the World Circuits by roughly 100%.
- Added high rewards for all Gold/Bronze results clearing the Circuit Experience.
- Online Races rewards increase.
- Add 8 new 1-hour Endurance Race events to Missions. So expect higher rewards.
- Increase the non-paid credit limit in player wallets from 20M to 100M.
- Expand the number of Used and Legend cars available at any time.
- With time, we will increase the payout value of limited time rewards.
- New World Circuit events.
- Missions now include 24-hour endurance races.
- Online Time Trials added, with rewards based on the player's time difference from the leader.
- Make cars sellable.
The full list of updates and changes can be found here.
Read the original post.